Objektorientiertes Programmieren mit C++
Inhalt
Objekte
C++ ist nicht nur das bessere C, sondern bietet dem Entwickler die Möglichkeit, objektorientiert zu programmieren. Dies verlangt neben dem Erlernen neuer Sprachelemente auch eine neue "objektorientierte" Denkweise. In Form eines Tutorials soll hier mit dieser Denkweise vertraut gemacht werden.
Herkömmliche Softwareentwicklung bestand oftmals darin, zur Lösung eines vorgegebenen Problems Algorithmen zu entwerfen und diese in Prozeduren zu gießen, die in einer Programmiersprache - wie zum Beispiel C - formuliert sind. Man spricht daher auch von prozeduraler Programmierung.
Betrachtet man jedoch die reale Welt, so stellt man fest, daß die Dinge sich hier nicht in einer abstrakten prozeduralen Weise bewegen. Diesen Bruch zwischen realer Welt und Softwareentwicklung versucht der objektorientierte Ansatz zu überwinden. Analysiert man seine materielle Umgebung, so stellt man fest, daß diese im wesentlichen aus Objekten besteht, die in verschiedener Art und Weise miteinander agieren. So könnte es in unserer unmittelbaren Umgebung gerade ein Objekt Fahrrad geben.
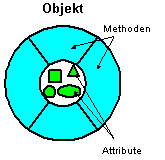 Nimmt man das Fahrrad noch weiter unter die Lupe, erkennt man, daß dieses Fahrrad bestimmte Eigenschaften bzw. Attribute (wie Farbe, Größe, momentane Geschwindigkeit) besitzt und daß es Methoden gibt, diese Eigenschaften zu verändern (z.B. die Methode "Tritt schneller", die zu einer Erhöhung der Geschwindigkeit führen wird oder die Methode "Bremse", die das Gegenteil bewirken sollte).
Nimmt man das Fahrrad noch weiter unter die Lupe, erkennt man, daß dieses Fahrrad bestimmte Eigenschaften bzw. Attribute (wie Farbe, Größe, momentane Geschwindigkeit) besitzt und daß es Methoden gibt, diese Eigenschaften zu verändern (z.B. die Methode "Tritt schneller", die zu einer Erhöhung der Geschwindigkeit führen wird oder die Methode "Bremse", die das Gegenteil bewirken sollte).
Transformiert man diese Erkenntnis aus der realen in die Software-Welt, so kann man formulieren:
Ein Software-Objekt ist ein Bündel aus Attributen und darauf bezogenen Methoden.
Klassen
Klassen als Bauplan
Wenn wir verschiedene Fahrrad-Objekte der realen Welt genauer betrachten, so stellen wir fest, daß alle diese Fahrrad-Objekte ähnlich sind: Alle besitzen Bremsen, alle haben irgendeine Farbe usw. Es muß also einen Bauplan geben, der beschreibt, wie ein Fahrrad grundsätzlich auszusehen hat. Alle Fahrrad-Objekte sind nach diesem Bauplan erstellt worden - deswegen ist es uns auch möglich, ein beliebiges Fahrrad zu fahren, wenn wir einmal das Fahrradfahren gelernt haben! Wieder übertragen wir diese Erkenntnis in die Softwarewelt:
Eine Klasse ist ein Bauplan, welcher die Attribute und Methoden definiert, die alle Objekte einer bestimmten Art besitzen.
 Die Abbildung zeigt eine Klasse StockItem in der sogenannten UML (unified modelling language) Notation. Diese Klasse könnte in einem Programm zur Aktienanalyse verwendet werden. Ein solches Programm muß viele verschiedene Aktien-Objekte verwalten können. Damit dies effektiv geschehen kann, sollten alle diese verschiedenen Objekte jedoch nach einem einheitlichen Bauplan - der Klassendefinition - erstellt werden.
Die Abbildung zeigt eine Klasse StockItem in der sogenannten UML (unified modelling language) Notation. Diese Klasse könnte in einem Programm zur Aktienanalyse verwendet werden. Ein solches Programm muß viele verschiedene Aktien-Objekte verwalten können. Damit dies effektiv geschehen kann, sollten alle diese verschiedenen Objekte jedoch nach einem einheitlichen Bauplan - der Klassendefinition - erstellt werden.
Der Name der Klasse steht in der UML-Notation im oberen Drittel des Rechtecks. Im mittleren Drittel stehen die Attribute. Unsere Beispielklasse StockItem definiert die zwei Attribute m_name und m_value, d.h. den Namen der Aktie und den momentanen Kurswert. Das Minuszeichen vor den Attributen bedeutet, das diese private Mitglieder der Klasse sind, d.h. von außen kann nicht direkt auf sie zugegriffen werden.
Im unteren Drittel stehen die Methoden der Klasse StockItem. Das Pluszeichen vor ihnen zeigt, daß sie public sind, d.h. die Methoden dürfen von anderen Objekten aufgerufen werden. Damit zeigt sich das Prinzip der Kapselung: Anstatt auf das Attribut m_value direkt zuzugreifen, müssen andere Objekte die Zugriffsmethoden setValue() und getValue() benutzen! So hat der Entwickler der Klasse die Möglichkeit, in setValue() noch zusätzliche Abfragen, z.B. bezüglich der Gültigkeit des Parameters, einzubauen.
Aufmerksamen Lesern wird bei Betrachtung der Abbildung eine Erweiterung von C++ gegenüber C nicht entgangen sein: Funktionen werden in C++ nicht nur - wie in C - durch den Namen, sondern durch Namen und Parameteranzahl und -typ unterschieden! So kann es die Methode setValue() zweimal geben: Einmal mit einem Parameter vom Typ double und mit einem vom Typ const char*. Der Compiler erkennt beim Aufruf dieser Methode anhand des Parametertyps selbsttätig, welche Variante er verwenden muß.
Klassendefinition
Es ist angebracht, C++-Klassendefinitionen generell in Headerdateien (das sind die mit der Extension .h) vorzunehmen. Guter Programmierstil ist dabei, jeweils eine Headerdatei je Klasse vorzusehen und diese auch wie die Klasse zu benennen.
Die Klassendefinition für StockItem wird also in der Headerdatei mit dem Namen StockItem.h vorgenommen:
/* 1 */ #ifndef StockItem_h /* 2 */ #define StockItem_h 1 /* 3 */ /* 4 */ class StockItem { /* 5 */ /* 6 */ public: /* 7 */ // ctor /* 8 */ StockItem( const char* name = "", double val = 0.0); /* 9 */ /* 10 */ // copy ctor /* 11 */ StockItem( const StockItem &right); /* 12 */ // dtor /* 13 */ virtual ~StockItem(); /* 14 */ // assignment operator /* 15 */ const StockItem& operator=(const StockItem &right); /* 16 */ /* 17 */ // public member functions /* 18 */ virtual const char* getName() const; /* 19 */ virtual void setValue( double val); /* 20 */ virtual void setValue( const char* val); /* 21 */ virtual double getValue() const; /* 22 */ /* 23 */ private: /* 24 */ // private member variables /* 25 */ char *m_name; /* 26 */ double m_value; /* 27 */ }; /* 28 */ /* 29 */ #endif
Die Klassendefinition beginnt mit dem Schlüsselwort class gefolgt vom Namen der Klasse (Zeile 4). Die eigentliche Definition wird von geschweiften Klammern { } umschlossen. Die Schlüsselwörter public und private trennen die im letzten Abschnitt besprochenen öffentlichen (Zeilen 7 bis 21) und privaten (Zeilen 24 bis 26) Bereiche der Definition ab. Es gibt außerdem noch die Möglichkeit, mittels protected Variablen und Methoden zu deklarieren, die ausschließlich abgeleiteten Klassen zur Verfügung stehen sollen. Dazu mehr später mehr beim Thema Vererbung.
Die Deklaration der öffentlichen Methoden (Zeilen 18 bis 19) und der privaten Variablen (Zeilen 25 und 26) erfolgt genauso wie eine normale Deklaration von Funktionen bzw. Variablen in C. Bei den Funktionen fällt die Verwendung der Spezifikation virtual auf. Dies ist wiederum für das Thema Vererbung wichtig und wird später besprochen. Man macht jedoch nicht viel verkehrt, wenn man direkt jeder Funktion von vorneherein diese Spezifikation verpaßt.
Auf den Zeilen 7 bis 15 werden Constructor, Copy-Constructor, Destructor und Assignment Operator deklariert. Um den Sinn dieser Elemente verstehen zu können, müssen wir zunächst auf den Objektlebenszyklus eingehen
PS: Noch ein kleiner Tip: Der Compiler produziert die wunderlichsten Fehlermeldungen, wenn der Programmierer das Semikolon am Ende der Klassendefinition (Zeile 27) vergißt...
Objektlebenszyklus
Der Lebenszyklus eines C++-Objektes besteht aus den Abschnitten
- Erzeugung
- Benutzung
- Zerstörung
Erzeugen eines Objektes
Das Erzeugen eines Objektes erfogt durch Aufruf des Konstruktors (kurz ctor) des Objektes. Dies kann sowohl statisch durch Variablendeklaration als auch dynamisch mittels des new Operators geschehen:
StockItem bay; // default constructor, statisch StockItem dte( "Deutsche Telekom AG", 50.34); // spezieller ctor, statisch StockItem *bas = new StockItem( "BASF", 120.34); // spezieller ctor, dynamisch // der für bas nötige Speicherplatz wird auf dem Heap alloziert
Benutzen eines Objektes
Ein Objekt wird benutzt, indem eine seiner Methoden aufgerufen wird:
dte.setValue( 52.80); // ruft Methode StockItem::setValue() des Objektes dte auf a = bas->getValue(); // ruft Methode StockItem::getValue() des Objektes bas auf
Außerdem kann das komplette Objekt als Parameter an eine Funktion übergeben oder von dieser per return zurückgegeben werden. Erfolgt die Wertübergabe dabei per Value, so wird implizit der Copy Konstruktor des Objektes aufgerufen:
StockItem cnv( StockItem x) {
// ...
return x2;
// return per value: ruft den Copy Constructor von x2 auf
}
StockItem bas( "BASF", 120.34);
cnv( bas);
// parameter per value: ruft den Copy Constructor von bas auf
StockItem bas2 = bas;
// explizite Kopie: ruft den Copy Constructor von bas2 auf
Ebenso kann ein Objekt komplett einem anderen bereits existierenden Objekt zugewiesen werden, wenn dieses den gleichen Typ oder den Typ einer Basisklasse hat. Dann wird der Assignment Operator des Objektes aufgerufen:
StockItem x; StockItem y( "ABC", 22); x = y; // ruft den Assignment Operator von x auf
Zerstören eines Objektes
Wird ein Objekt nicht mehr benötigt, so sollte es zerstört werden, damit es keinen Speicherplatz mehr verbraucht. Bei der Zerstörung eines Objektes wird automatisch sein Destruktor (kurz dtor) aufgerufen. Im Falle eines dynamisch per new erzeugten Objektes wird dies mit dem Operator delete bewerkstelligt. Ein statisch erzeugtes Objekt wird automatisch zerstört, wenn bei der Programmausführung der Gültigkeitsbereich der statischen Deklaration verlassen wird:
delete bas; // der Destructor des Objektes bas wird aufgerufen und anschließend // der durch bas belegte Speicherplatz freigegeben if (x) { StockItem bmw; // ... } // der dtor des statisch angelegten Objektes bmw wird hier am Blockende // wegen des Verlassens des Gültigkeitsbereiches der Deklaration aufgerufen
Beachte:Der Destruktor eines Objektes wird in der Regel niemals direkt aufgerufen, sondern sein Aufruf erfolgt wie oben dargestellt implizit durch Verwendung von delete oder beim Verlassen des Gültigkeitsbereiches!
Objektimplementierung
Was uns nun noch zum ersten vollständigen C++-Programm fehlt, ist die Implementierung der einzelnen Methoden des Objektes StockItem.
Die Implementierung wird vorzugsweise in einer Datei mit Namen StockItem.cpp vorgenommen. Zu Beginn wird die Headerdatei StockItem.h inkludiert:
/* 1 */ #include "StockItem.h" /* 2 */ #include <cstdlib> /* 3 */ #include <cstring> /* 4 */ /* 5 */ StockItem::StockItem( const char* name /* = "" */, double val /* = 0.0 */) /* 6 */ { /* 7 */ m_name = new char[strlen(name)+1]; /* 8 */ strcpy( m_name, name); /* 9 */ m_value = val; /* 10 */ } /* 11 */ /* 12 */ StockItem::StockItem( const StockItem &right) /* 13 */ /* 14 */ { /* 15 */ /* 16 */ m_name = new char[strlen( right.m_name)+1]; /* 17 */ strcpy( m_name, right.m_name); /* 18 */ m_value = right.m_value; /* 19 */ } /* 20 */ /* 21 */ StockItem::~StockItem() /* 22 */ { /* 23 */ delete[] m_name; /* 24 */ } /* 25 */ /* 26 */ const StockItem& StockItem::operator=(const StockItem &right) /* 27 */ { /* 28 */ // handle self assignment /* 29 */ if (this != &right) { /* 30 */ delete[] m_name; /* 31 */ m_name = new char[strlen( right.m_name)+1]; /* 32 */ strcpy( m_name, right.m_name); /* 33 */ m_value = right.m_value; /* 34 */ } /* 35 */ /* 36 */ return *this; /* 37 */ } /* 38 */ /* 39 */ const char* StockItem::getName() const /* 40 */ { /* 41 */ return m_name; /* 42 */ } /* 43 */ /* 44 */ void StockItem::setValue( double val) /* 45 */ { /* 46 */ m_value = val; /* 47 */ } /* 48 */ /* 49 */ void StockItem::setValue( const char* val) /* 50 */ { /* 51 */ m_value = atof( val); /* 52 */ } /* 53 */ /* 54 */ double StockItem::getValue() const /* 55 */ { /* 56 */ return m_value; /* 57 */ }
Die Implementierung der öffentlichen Methoden für das Setzen und Auslesen der Werte der Attribute in den Zeilen 39 bis 57 enthält nichts besonderes, der Code dürfte für sich sprechen.
Interessanter ist der Konstruktor (Zeilen 5 bis 10): Da wir den Namen des StockItem in einer C-Zeichenkette vom Typ char* speichern wollen, muß zuerst der hierfür notwendige Speicherplatz allokiert werden (Zeile 7). Da wir in C++ programmieren, verwenden wir nicht das aus der C-Welt vertraute malloc, sondern den C++-Operator new[].
Ähnlich verhält sich die Sache beim Copy Konstruktor (Zeilen 12 bis 19): Hier ist das einzige Argument immer eine Referenz auf ein Objekt des gleichen Typs. Dessen Membervariablen müssen in die eigenen Variablen kopiert werden, damit eine 1:1 Kopie des Objektes entsteht. Wir erinnern uns: Der Copy Konstruktor wird bei Übergabe von Objekten per Value an oder aus Funktionen oder beim expliziten Kopieren verwendet.
Noch interessanter gestaltet sich die Sache beim Assignment Operator (Zeilen 26 bis 37): Hier existiert ja schon ein Objekt x, in das ein zweites Objekt y hineinkopiert wird! Also muß zuerst der von x belegte Speicherplatz freigegeben werden (Zeile 30), bevor die Variablen kopiert werden können. In der C++-Sprache bezeichnet man übrigens unser Objekt x als this. Der Bezug auf das eigene Objekt this ist so wichtig, daß this sogar ein reserviertes Wort in C++ ist und immer innerhalb von Objektfunktionen zur Verfügung steht. Der Assignment Operator gibt einen Zeiger auf das Objekt selbst (also auf this) zurück, schließlich wird er ja in Zuweisungen wie
StockItem x;
StockItem y( "ABC", 22);
x = y;
verwendet.
Übrigens hindert niemand den Programmierer, statt x = y die Zuweisung x = x hinzuschreiben! Dann haben wir den Fall des Self Assignments vorliegen: Ein Objekt wird sich selbst zugewiesen. Dann darf der Assignment Operator auch nichts weiter tun. Die Abfrage, ob Self Assignment vorliegt, findet in Zeile 29 statt.
Der mittels new[] vom Betriebssystem während der Objektkonstruktion explizit angeforderte Speicherplatz muß beim Zerstören des Objektes auch wieder ausdrücklich freigegeben werden. Wir erinnern uns: Beim Zerstören des Objektes wird automatisch sein Destruktor ausgeführt. Deswegen wird im Destruktor (Zeilen 21 bis 24) der für m_name angeforderte Speicherbereich mittels delete[] freigegeben.
Vererbung
Konzept
Vererbung erlaubt die Definition neuer Klassen auf der Basis von bestehenden Klassen. Dies ist ein grundlegendes Konzept objektorientierten Designs. 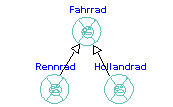 Weiter oben wurde der Begriff der Klasse als eine Art Bauplan für Objekte erklärt. Anhand des dort verwendeten Beispiels "Fahrrad" lassen sich weitere Parallelen zur realen Welt ziehen: Es fällt auf, daß es hier verschiedene Arten von Fahrrädern gibt: Rennräder, Montainbikes, Treckingräder und das gute alte Hollandrad. Warum sind alle diese verschiedenen Räder für uns als Fährräder erkennbar? Weil sie gewisse gemeinsame Eigenschaften haben: Alle haben zwei Räder, einen Lenker und lassen sich durch Tritt auf die Pedale fortbewegen. Zusätzlich zu diesen Gemeinsamkeiten bringen sie aber auch neue Eigenschaften ein: Montainbikes und Rennräder haben jeweils eine Gangschaltung, unterscheiden sich aber durch die Art der Bereifung.
Weiter oben wurde der Begriff der Klasse als eine Art Bauplan für Objekte erklärt. Anhand des dort verwendeten Beispiels "Fahrrad" lassen sich weitere Parallelen zur realen Welt ziehen: Es fällt auf, daß es hier verschiedene Arten von Fahrrädern gibt: Rennräder, Montainbikes, Treckingräder und das gute alte Hollandrad. Warum sind alle diese verschiedenen Räder für uns als Fährräder erkennbar? Weil sie gewisse gemeinsame Eigenschaften haben: Alle haben zwei Räder, einen Lenker und lassen sich durch Tritt auf die Pedale fortbewegen. Zusätzlich zu diesen Gemeinsamkeiten bringen sie aber auch neue Eigenschaften ein: Montainbikes und Rennräder haben jeweils eine Gangschaltung, unterscheiden sich aber durch die Art der Bereifung.
In objektorientierter Sprache könnte man also sagen: Die Klassen Montainbikes, Rennräder und Hollandräder erben von der Klasse Fahrräder gemeinsame Eigenschaften und fügen zusätzliche hinzu. Allgemein gilt:
- Klassen können definiert werden in Abhängigkeit von anderen Klassen: "A ist eine Art von B". In diesem Fall ist B die Basisklasse von A.
- Eine Klasse kann auch von mehreren Klassen erben: A ist eine Art von B und C (Mehrfachvererbung).
- Jede Klasse erbt die (öffentlichen) Attribute und Methoden ihrer Basisklasse(n).
- Jedoch kann jede Klasse eigene Variablen und Methoden hinzufügen.
Es ist wichtig zu verstehen, daß Vererbung nur in eine Richtung läuft: Ein Rennrad ist zwar immer auch ein Fahrrad, aber nicht jedes Fahrrad ist automatisch ein Rennrad. Wenn in C++ ein Objekt a der Klasse A definiert wird und die Klasse A von B abgeleitet ist, dann kann a jederzeit per Cast in ein Objekt vom Typ B umgewandelt werden. Die Umkehrung gilt nicht: Ein Objekt b der Klasse B kann in diesem Fall nicht in den Typ A umgewandelt werden!
Vererbung in C++
Die von uns bereits definierte und benutzte Klasse StockItem erlaubt die Speicherung eines Namens und eines dazugehörenden Wertes und ist zur Darstellung von Aktienkursen gedacht. Wer sich mit dieser Materie schon beschäftigt hat, der weiß, daß zu einer Aktie noch viele Informationen mehr gespeichert werden können. So gibt es neben dem (Tages- oder Wochen-)Schlusskurs (Close) noch Eröffnungs- (Open), Höchst- (High) und Tiefstkurs (Low). Wir wollen daher nun StockItem um die Möglichkeit erweitern, zusätzlich auch den Eröffnungskurs abfragen und setzen zu können.
Diese Erweiterung soll jedoch nicht durch Verändern der existierenden Klasse StockItem erfolgen - diese Klasse wird bereits in vielen Softwareprojekten benutzt und eine Änderung ihrer Funktionalität könnte unter Umständen böse Auswirkungen haben. Auch wollen wir das Rad nicht völlig neu erfinden - vorhandener Code soll so weit wie möglich wiederverwendet werden. Dies alles erreichen wir dadurch, daß wir eine neue Klasse StockItemOC definieren, die von der vorhandenen Klasse StockItem abgeleitet ist:
/* 1 */ #ifndef StockItemOC_h /* 2 */ #define StockItemOC_h 1 /* 3 */ /* 4 */ class StockItemOC : public StockItem { /* 5 */ /* 6 */ public: /* 7 */ // ctor /* 8 */ StockItemOC( const char* name = "", double open = 0.0, double close = 0.0); /* 9 */ /* 10 */ // copy ctor /* 11 */ StockItemOC( const StockItemOC &right); /* 12 */ // dtor /* 13 */ virtual ~StockItemOC(); /* 14 */ // assignment operator /* 15 */ const StockItemOC& operator=(const StockItemOC &right); /* 16 */ /* 17 */ // public member functions /* 18 */ virtual void setValue( double val); /* 19 */ virtual double getValue() const; /* 20 */ virtual void setOpen( double val); /* 21 */ virtual double getOpen() const; /* 22 */ virtual void setClose( double val); /* 23 */ virtual double getClose() const; /* 24 */ /* 25 */ private: /* 26 */ // private member variables /* 27 */ double m_open; /* 28 */ double m_close; /* 29 */ }; /* 30 */ /* 31 */ #endif
Die einzige Erweiterung gegenüber der uns bekannten Klassendefinition ist, daß zu Beginn in Zeile 4 die Basisklasse nach dem Doppelpunkt und dem Schlüsselwort public angegeben wird.
Welche Auswirkung hat diese Vererbungsbeziehung nun auf das Verhalten unserer neuen Klasse StockItemOC? Schauen wir uns dazu das UML-Diagramm an: 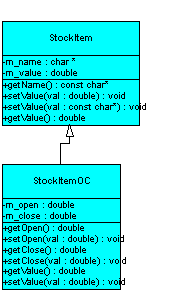
- StockItemOC erbt die Methode getName() von StockItem. Diese Methode braucht also nicht noch einmal implementiert zu werden.
- StockItemOC überschreibt die Methoden setValue() und getValue() von StockItem. Diese Methoden müssen anders implementiert sein, da StockItemOC ja zwei Kurswerte statt einem zur Auswahl hat.
- StockItemOC hat die zusätzlichen Methoden getOpen(), setOpen(), getClose() und setClose(), um die zusätzliche gewünschte Funktionalität abbilden zu können.
- StockItemOC erbt die Variablen m_name und m_value von StockItem. Da diese Variablen dort aber als private deklariert sind, haben die Methoden von StockItemOC keinen Zugriff auf diese Variable - außer natürlich getName(), denn diese ist ja auch von StockItem geerbt.
- StockItemOC deklariert die zusätzlichen privaten Variablen m_open und m_close.
Implementierung der abgeleiteten Klasse
Zunächst wollen wir einen Blick auf die Implementierung der abgeleiteten Klasse in StockItemOC.cpp werfen:
/* 1 */ #include <cstdlib> /* 2 */ #include "StockItem.h" /* 3 */ #include "StockItemOC.h" /* 4 */ /* 5 */ StockItemOC::StockItemOC( const char* name, double open, double close) /* 6 */ : StockItem(name), m_open(open), m_close(close) /* 7 */ { } /* 8 */ /* 9 */ StockItemOC::StockItemOC( const StockItemOC &right) /* 10 */ : StockItem(right), m_open(right.m_open), m_close(right.m_close) /* 11 */ { } /* 12 */ /* 13 */ StockItemOC::~StockItemOC() /* 14 */ { } /* 15 */ /* 16 */ const StockItemOC& StockItemOC::operator=(const StockItemOC &right) /* 17 */ { /* 18 */ // handle self assignment /* 19 */ if (this != &right) { /* 20 */ StockItem::operator=(right); /* 21 */ m_open = right.m_open; /* 22 */ m_close = right.m_close; /* 23 */ } /* 24 */ /* 25 */ return *this; /* 26 */ } /* 27 */ /* 28 */ void StockItemOC::setValue( double val) /* 29 */ { /* 30 */ m_close = val; /* 31 */ } /* 32 */ /* 33 */ double StockItemOC::getValue() const /* 34 */ { /* 35 */ return m_close; /* 36 */ } /* 37 */ /* 38 */ void StockItemOC::setOpen( double val) /* 39 */ { /* 40 */ m_open = val; /* 41 */ } /* 42 */ /* 43 */ double StockItemOC::getOpen() const /* 44 */ { /* 45 */ return m_open; /* 46 */ } /* 47 */ /* 48 */ void StockItemOC::setClose( double val) /* 49 */ { /* 50 */ m_close = val; /* 51 */ } /* 52 */ /* 53 */ double StockItemOC::getClose() const /* 54 */ { /* 55 */ return m_close; /* 56 */ }
Interessant ist hier zunächst wieder der Konstruktor (Zeilen 5 bis 7): Im Gegensatz zum Konstruktor von StockItem weiter oben erfolgt die Initialisierung der Variablen (m_open und m_close) hier nicht im Funktionsrumpf, sondern in einer Initialisierungsliste. Dies schafft vor allem Performancevorteile bei der Konstruktion der Objekte. Ferner müssen wir bedenken, daß die in der Basisklasse als privat deklarierten Variablen (wie m_name) hier nicht direkt angesprochen werden können. Um diese trotzdem korrekt zu initialisieren, wird der Konstruktor der Basisklasse in der Initialisierungsliste aufgerufen (Zeile 6).
Gleiches gilt für den Copy Konstruktor (Zeilen 9 bis 11), der den Copy Konstruktor der Basisklasse in seiner Initialisierungsliste aufführt. Und auch der Assignment Operator muss den der Basisklasse explizit aufrufen (Zeile 20). Lediglich beim Destruktor (Zeilen 13 und 14) ist das Verhalten anders. Hier stellt die C++ Laufzeitumgebung sicher, daß alle Destruktoren voneinander abgeleiteter Klassen in der richtigen Reihenfolge aufgerufen werden. Da in StockItemOC kein dynamisch allozierter Speicher verwendet wird, braucht der Destruktor auch nichts weiter zu tun.
Die restlichen Methoden von StockItemOC dienen dem Setzen und Auslesen der privaten Variablen und bieten nichts Neues.
Verwendung abgeleiteter Klassen
Die Verwendung von abgeleiteten Klassen soll nun anhand der Klasse StockItemOC in einem kleinen Testprogramm demonstriert werden.
Am Anfang der Programmdatei müssen die benötigten Headerfiles inkludiert werden:
#include <iostream> #include <vector> #include <algorithm> #include <iterator> #include "StockItem.h" #include "StockItemOC.h" using namespace std; int main( int argc, char** argv) {
Als erste Übung werden wir zwei StockItem Objekte und ein StockItemOC Objekt statisch anlegen und diese dann zur Ausgabe einiger Werte benutzen:
StockItem a( "BAY", 34.9);
StockItem b( "BAS");
StockItemOC c( "DTE", 57.0, 59.4);
b.setValue( 24.2);
cout << a.getName() << ": " << a.getValue() << endl;
cout << b.getName() << ": " << b.getValue() << endl;
cout << c.getName() << ": " << c.getValue() << " ("
<< c.getOpen() << " -> " << c.getClose() << ")\n";
Dies bietet auf den ersten Blick nichts neues. Beim zweiten Hinsehen erkennen wir, daß in der letzten Zeile die Methode getName() des Objektes c, welches vom Typ StockItemOC ist, aufgerufen wird. Die Klasse StockItemOC hat aber gar keine Methode getName() definiert! Mit dem neu erworbenen Wissen über Vererbung ist jedoch klar, was passiert: Es wird einfach die von der Klasse StockItem geerbte Methode verwendet!
Interessant ist auch die Verwendung der Methode getValue(). Diese gibt es sowohl in StockItem als auch in StockItemOC. In diesem Beispiel ist jedoch relativ einfach zu verstehen, was passiert - sowohl für uns als auch für den C++-Compiler: In der letzten Zeile wird StockItemOC::getValue() aufgerufen, in den beiden Zeilen davor StockItem::getValue(). Das ist deshalb klar, weil der Typ der Objekte a, b und c bereits zur Übersetzungszeit bekannt ist und der Compiler entscheiden kann, welchen Methodenaufruf er verwenden muß. Dies wird auch als statische oder frühe Bindung bezeichnet.
Was passiert jedoch, wenn der Compiler beim Übersetzen den genauen Typ des Objektes noch nicht kennt? Sehen wir uns die Fortsetzung des Programmes an:
StockItem *astocks[3];
astocks[0] = &a;
astocks[1] = &b;
astocks[2] = &c; // cast from StockItemOC* to StockItem*
for (int i = 0; i < 3; ++i) {
cout << astocks[i]->getName() << ": " << astocks[i]->getValue() << endl;
}
Beim Aufruf astocks[i]->getValue() muß je nachdem, ob der in astocks stehende Pointer auf ein Objekt vom Typ StockItem (bei Index 0 und 1) oder vom Typ StockItemOC (Index 2) zeigt, eine andere Methode aufgerufen werden. Dies kann erst zur Laufzeit entschieden werden, man spricht dann von dynamischer oder später Bindung. Wie kann nun aber das Laufzeitsystem entscheiden, welchen Typ das Objekt hat? Der Schlüssel hierzu ist die sogenannte vtable, in der die spezifischen Funktionssignaturen für jedes Objekt abgelegt sind. Eine Funktionssignatur wird jedoch nur dann richtig in die vtable eingetragen, wenn die Funktionen in der Klassendefinitionen als virtual deklariert sind. Dies haben wir zum Glück in unseren Definitionen schon getan, so daß das Programm wie erwartet arbeitet. Folgende Regel sollte man sich beim Umgang mit C++ jedoch verinnerlichen:
Deklariere alle Memberfunktionen - inklusive des Destruktors - als virtual, wenn Du die Absicht hast, Vererbungsmechanismen zu verwenden!
Zum Schluß noch eine fortgeschrittene Anwendung unserer Objekte. Statt in ein Array werden sie in einen STL-Vektor gepackt. Anschließend werden die Objekte nach ihrem Wert (getValue()) sortiert und ausgegeben. Das alles funktioniert auch dann, wenn der Vektor sowohl Objekte vom Typ StockItem* als auch StockItemOC* enthält, weil wieder dynamische Bindung zum Einsatz kommt:
// get the stock items odered by price
vector<StockItem*> stocks;
stocks.push_back(&a);
stocks.push_back(&b);
stocks.push_back(&c); // cast from StockItemOC* to StockItem*
sort(stocks.begin(), stocks.end(), CompareStockPrice());
cout << endl << "stock items odered by price\n";
reverse_copy( stocks.begin(), stocks.end(), ostream_iterator<StockItem*>(cout));
}
Für die richtige Sortierung und die Ausgabe sind noch zwei Hilfsfunktionen notwendig, die vor main() in die Programmdatei eingefügt werden können: CompareStockPrice ist ein sogenannter functor. Er wird als Parameter an den Sortieralgorithmus sort übergeben und dient zum Vergleich zweier Objekte vom Typ StockItem. Die zweite Funktion ist der Ausgabeoperator für ein StockItem Objekt. Dieser wird im Alorithmus reverse_copy über den ostream_iterator verwendet.
// compare two stock prices class CompareStockPrice { public: int operator()( const StockItem* s1, const StockItem* s2) { return s1->getValue() < s2->getValue(); } }; // operator<< for class StockItem // write name and value to output stream ost ostream& operator<<( ostream& ost, const StockItem* item) { ost << item->getName() << ": " << item->getValue() << endl; return ost; }
Wie man sieht, reicht es völlig aus, die Hilfsfunktionen für die Klasse StockItem zu implementieren. Es ist beim Aufruf der Funktion dann egal, ob der aktuelle Parameter auf ein Objekt vom Typ StockItem oder StockItemOC zeigt. Dies ist ein Resultat (und Vorteil) der von uns implementierten Vererbungshierarchie.